CS231n Convolutional Neural Networks for Visual Recognition
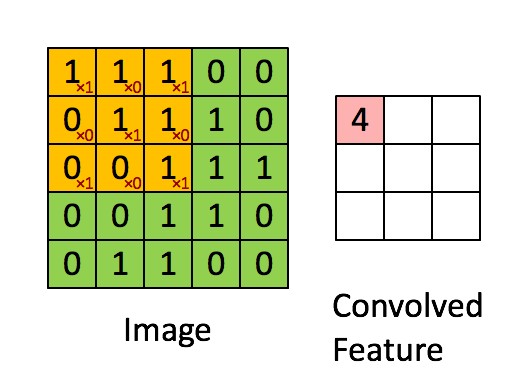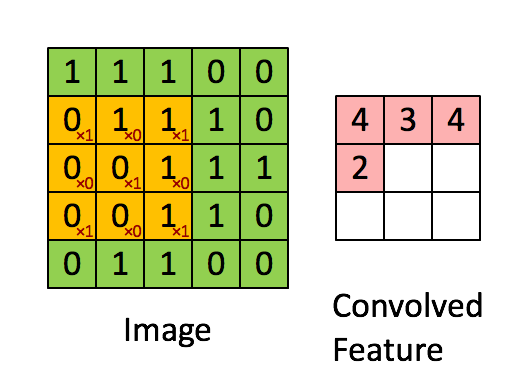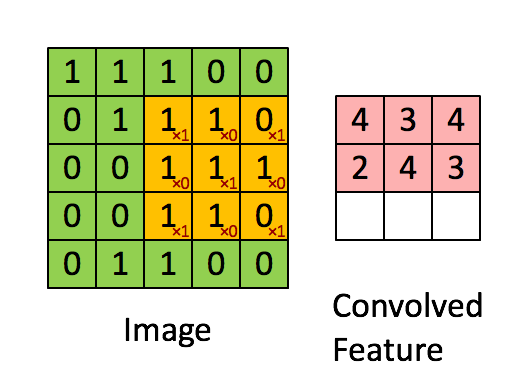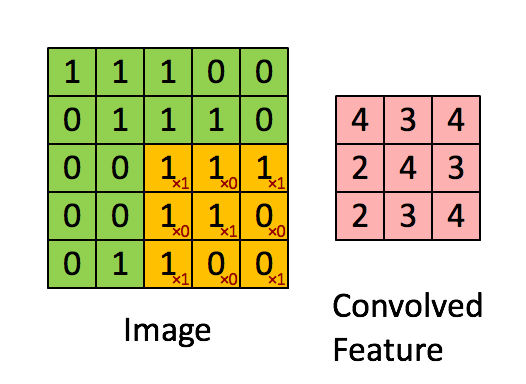
extract local features by using convolution kernel/filter with shape (hwd), where the depth (d) is determined by the number of input channels(depth of input image).
Stride: avoid overfiting
stride=1, convolution kernel(cube 331)

in image processing and speech recognition, if use fully connected neural network, such a large quantity of model parameters is usually difficult to converge, resulting in poor performance
Convolutional Neural Networks are very similar to ordinary Neural Networks from the previous chapter: they are made up of neurons that have learnable weights and biases. Each neuron receives some inputs, performs a dot product and optionally follows it with a non-linearity. The whole network still expresses a single differentiable score function: from the raw image pixels on one end to class scores at the other. And they still have a loss function (e.g. SVM/Softmax) on the last (fully-connected) layer and all the tips/tricks we developed for learning regular Neural Networks still apply.
So what changes? ConvNet architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties into the architecture. These then make the forward function more efficient to implement and vastly reduce the amount of parameters in the network.
Local Features Are the Key
assumption: if one feature is useful to compute at some spatial position), then it should also be useful to compute at a different position due to the translationally-invariant structure of images.